2024. 3. 4. 16:45ㆍProject 해축갤/데이터베이스
예전에
1. DB가 부러졌고
2. 부러진지도 몰랐고
3. 알고난 이후에는 복구하려고 갖은 방법을 써봤지만
결국에는 복구를 하지 못하고 지우고 새롭게 설치를 했었습니다.
백업 및 복구 실패 글 링크 : https://xpmxf4.tistory.com/93
MySQL 데이터베이스 복구 실패: 실험에서 배운 교훈과 데이터베이스 관리 전략
? DB 가 죽어버렸다. 껐다 켜면 되겠지라는 생각으로 다음 명령어를 쳤는데 brew services restart mysql 여전히 안된다. 원인 분석 그래서 로그를 확인하기 위해 ‘/usr/local/mysql/data/mysqld.local.err’ 을 까
xpmxf4.tistory.com
그래서 미리미리 백업을 해야한다는 것과, 복구 시스템을 갖춰야 함을 뼈저리게 느껴
이번에 한번 백업 시스템을 갖춰보기로 했습니다.
이런 고민을 하자마자 가장 쉬운 해결법을 생각했습니다.

RDS 사용(=돈으로 해결) 하기! 가 바로 생각난 방법입니다.
사실 뭐 어떻게 보면 가장 좋은 해결책일수도 있습니다.
상당히 빠른 시간안에 해결이 가능하다는 측면에서,,,
솔직히 적은 금액이면 사용할 용의도 있습니다.
그래서 쉬운 해결책은 얼마나 돈이 드는지 MySQL기준 요금 측정을 해봤습니다.
# 요금 측정
https://calculator.aws/#/createCalculator/RDSMySQL
위 사이트에서 RDS 사용 옵션을 선택 후 요금에 대한 측정을 할 수 있습니다.
제공된 링크로 들어가 취준생 국룰 t3.micro 옵션 선택후

그 외 기본적으로 선택된 옵션으로 요금 측정을 해보니 다음과 같았습니다.

글 작성하는 2/27 오늘 기준 환율이 다음과 같으니,,,
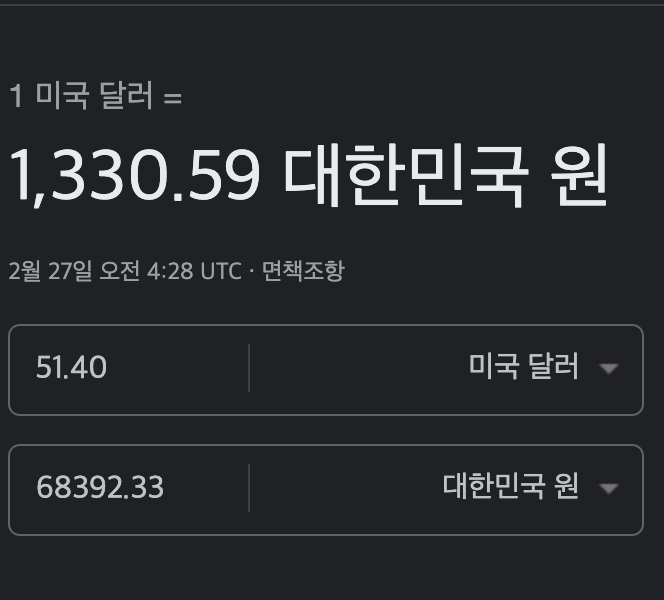
한달에 68,000원?
아 ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ

그래서 DIY(Do It Yourself) 하자! 라는 생각으로
직접 복구 및 백업 시스템을 구축해보기로 했습니다 ㅎㅅㅎ,,,
#전체 프로세스
풍문으로 들은 말, 구글링을 통해 백업 서비스를 바로 집어넣을 수도 있겠지만,
모든 기술의 도입에 있어서 사전에 다방면으로 고민을 해봐야 합니다.
그래서 다음과 같은 step으로 고려 플랜을 짜봤습니다.
💡 STEPS
### **1단계: 현재 시스템의 데이터 구조와 복구 요구사항 분석**
### **2단계: 적절한 백업 및 복구 전략 선택**
### **3단계: 백업 및 복구 도구 및 방법 선택
————————— 이 글은 일단 여기까지 ——————————
### **4단계: 백업 세팅**
### **5단계: 복구 세팅**
### **6단계: 검토 및 업데이트**
1. 현재 시스템의 데이터 구조와 복구 요구사항 분석
이 단계가 어떻게 보면 가장 중요하다고 생각할 수 있습니다.
💡 무엇을, 어떻게 백업할지 알아야 효율적으로 계획을 세울 수 있기 때문입니다!
이 분석을 통해 중요한 데이터가 무엇인지, 얼마나 자주 백업해야 하는지,
어떤 백업 방식이 가장 적합한지를 알 수 있습니다.
이 초기 단계 없이 백업 계획을 세우려고 하면, 중요한 데이터를 놓칠 수도 있고,
필요 이상으로 많은 자원을 낭비할 수도 있습니다.
그리고 이러한 중요한 여부는 서비스에서의 데이터가 가지는 중요도에 따라 다릅니다.
간단히 말해, **"올바른 백업 계획을 세우려면 무엇을 백업해야 하는지
서비스 특성을 통해 정확히 알아야 합니다."
그렇다면 이제 해축갤 서비스의 특성에 대해 알아보겠습니다.
1-1. 해축갤의 서비스 특성
해축갤은 다양한 주제에 대한 활발한 토론(?)과 정보 공유(?)의 장으로서,
특히 축구에 관련된 다양한 논의가 활발히 이뤄집니다. (논의라기보다 거의 욕설에 가깝지만,,, 🙈🙈,,,)

나무위키에서 이에 대한 구체적인 특징을 찾아보면 다음과 같습니다.
나무위키에 정리된 해축갤 특성
1. 해축갤은 다양한 주제와 축구 중계를 다룹니다.
2. 큰 이벤트 시에는 커뮤니티 활동이 활발해집니다.
3. 유명 축구 인물 및 신예들에 대한 논의가 활발합니다.
[출처] : https://namu.wiki/w/해외축구 갤러리#s-3
특성을 토대로 RPO와 RTO 가 이 서비스에서 가지는 중요도를 한번 보겠습니다.
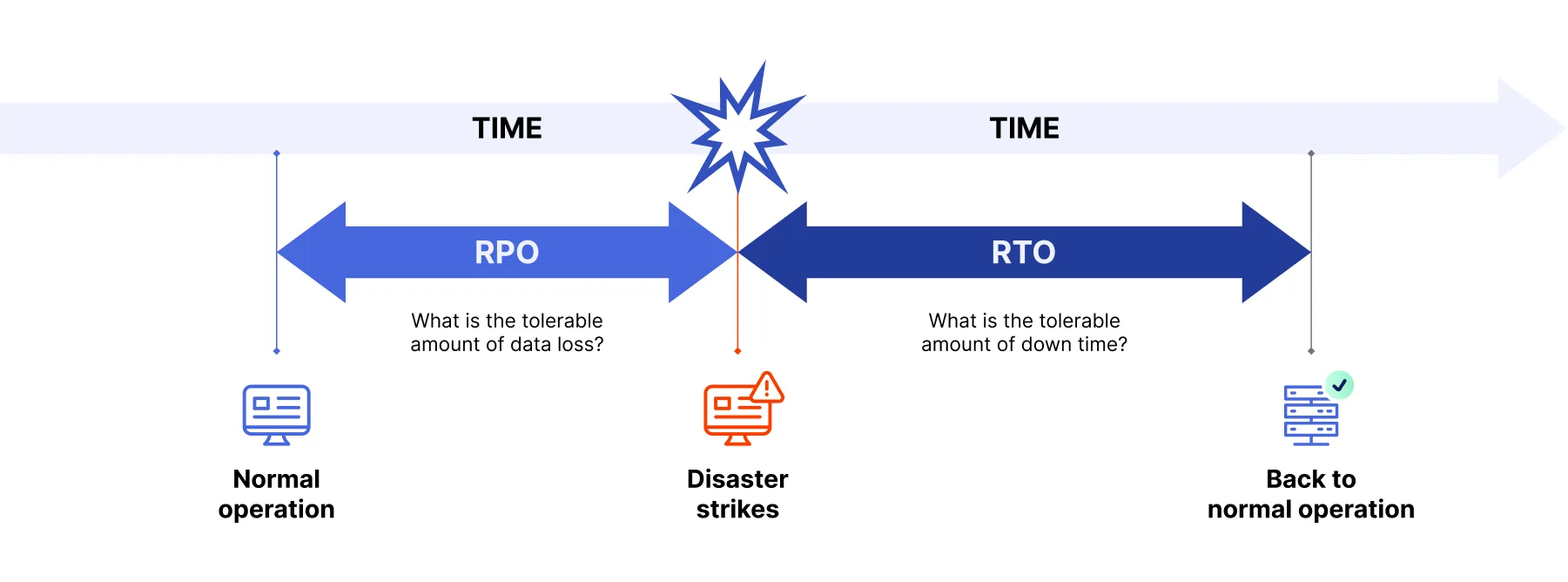
💡 잠깐 RPO, RTO 란?
RPO (복구 지점 목표): 데이터의 복구가 가능한 마지막 시점을 의미합니다.
즉, 손실될 수 있는 데이터의 최대 허용 시간을 의미.
RTO (복구 시간 목표): 시스템이나 애플리케이션의 다운타임 후 정상 작동 상태로 복구되는 데 필요한 시간을 의미합니다.
다운된 후 얼마나 빨리 복구가 되어야 하는가를 의미
1-2. 해축갤에서의 RPO vs RTO
해축갤에서는 사용자들이 실시간으로 의견을 나누는 활동이 핵심이기 때문에,
특정 시점 이전의 데이터 손실(RPO)이 큰 영향을 미치지 않을 수 있습니다.
대신, 커뮤니티의 활발한 참여와 실시간 논의를 유지하기 위해서는
시스템이나 서비스가 문제 발생 후 가능한 한 빠르게 복구되는 것(RTO)이 매우 중요합니다.
이는 대규모 이벤트나 경기 중 실시간 소통이
커뮤니티 활성도와 만족도에 직접적인 영향을 미치기 때문입니다.
따라서 해축갤과 같은 온라인 커뮤니티에서는 RTO >>> RPO 입니다.
2. 적절한 백업 전략 선택
실시간성과 사용자 참여가 매우 중요하다는 것을 봤으니,
이제 RTO(복구 시간 목표)를 최소화하는 방법을 선택해야 합니다.
이를 위해 다음과 같은 접근 방식들을 고려했습니다.
2-1. 실시간 데이터 복제 (Real-time Data Replication)
- 기본 : master 의 데이터를 실시간으로 replica 에 동기화
- 구현 방법 : master-slave, group replication, galera cluster
- 장단점 :
- 장: 데이터 손실 최소화, 거의 즉각적인 복구가 가능
- 단: 높은 비용과 복잡성, 복제 서버의 지속적인 유지 관리 필요.
- 적합성 : 데이터의 지속적인 가용성이 필요한 경우 적합
- RPO & RTO : RPO는 거의 0에 가깝고, RTO도 매우 짧다
2-2. 빈번한 증분 백업 (Frequent Incremental Backups)
- 기본 설명 : 정해진 시간 간격으로 변경된 데이터만 백업하는 방식입니다.
- 구현 방법 : cron 으로 mysqldump 예약, mysqlbinlog 으로 변경사항 추출 및 변경 반영
- 장단점 :
- 장점 : 스토리지 사용량 최적화, 전체 백업보다 빠른 백업 시간.
- 단점 : 복구 과정을 사용자가 일일이 짜야함.
- 적합성 : 데이터 변경 빈도가 높지만, 즉각적인 복구가 필수적이지 않은 경우에 적합
- RPO & RTO : RPO는 증분 백업 간격에 따라 달라지며, RTO는 복구 과정의 복잡성으로 인해 상대적으로 길다.
위 2가지 방법중 RTO가 더 낮은 실시간 데이터 복제 방식을 선택하기로 했습니다.
이 외에도 스냅샷, 오프사이트, 다중 위치 백업등이 있다만,
이들은 보통 클라우드 환경이나 여러 데이터 센터에 분산하는 방법이라 배제했습니다!
3. 백업 도구 및 방법 선택 (실시간 데이터 복제 방식)
실시간 데이터 복제 방식중 다양한 옵션을 고려한 끝에 다음과 같이 구성했습니다.
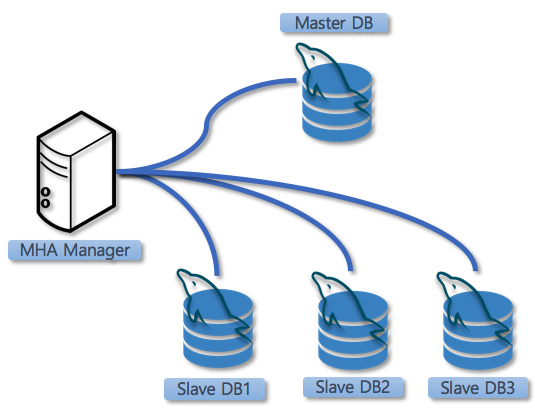
MySQL의 기본 복제 기능을 활용한 master-slave 구성 + 자동 승격을 위한 MHA
이러한 결정을 내리게 된 과정을 단계별로 설명드리겠습니다.
단계 1: 서비스 요구사항 분석
실시간성이 중요한 서비스 특성상, 데이터 복구 시간 목표(RTO)를 최소화하는 것을 핵심 요소로 판단했습니다.
이는 사용자 경험을 유지하고 서비스의 연속성을 보장하기 위해 필수적입니다.
단계 2: 복제 방식의 선택 및 비교
복제 방식을 결정하기 위해
- MySQL Replication (master-slave),
- Galera Cluster,
- MySQL Group Replication
세 가지 주요 방식을 고려했습니다.
1. MySQL Replication (master-slave)
- 단일 마스터에서 여러 슬레이브로 데이터를 복제합니다.
이 방식은 구성이 간단하고, 마스터에 장애가 발생할 경우 슬레이브를 승격시키는 과정이 비교적 단순합니다.
2. Galera Cluster (Multi-master)
- 모든 노드가 쓰기 작업을 수행할 수 있는 멀티마스터를 구성합니다.
이 방식은 고가용성을 제공하지만, 구성과 관리의 복잡성이 증가합니다.
또한, 모든 쓰기 작업이 각 노드에 동기화될 때까지 확인 응답(ack)을 받아야 하므로,
네트워크 지연에 민감하고 상황에 따라 성능이 느려질 수 있습니다.
이는 실시간성이 중요한 해축갤 서비스에서는 큰 단점이 될 수 있습니다.
3. MySQL Group Replication:
- 자동 멤버십 관리와 실패 감지 및 복구 기능을 제공하며, 싱글마스터 또는 멀티마스터 구성을 지원합니다.
고가용성을 제공하지만, Group Replication 역시 모든 변경사항에 대한 동기화 확인이 필요하므로,
네트워크 지연이나 구성 오류가 성능에 영향을 줄 수 있습니다.
단계 3: 자동 승격(복구)의 필요성 인식
서비스의 높은 가용성을 유지하려면 단순히 데이터를 복제하는 것만으로는 충분하지 않습니다.
백업까지는 됐지만, 여전히 '복구' 라는 미션이 남아있기 때문입니다.
Master-Slave 구조에서 특히 master 에 문제가 생길 경우, 서버에 장애가 생기게 됩니다.
이떄 수동으로 슬레이브 서버를 마스터로 승격시켜 해결가능하지만 단점이 2가지 있습니다.
- 사람이 일일이 복구해야한다.
- 복구하는 시간이 결국 장애시간이다.
그래서 이를 자동으로 승격시키는 방법이 필요합니다.
단계 4: MHA (MySQL Master HA)의 선택
장애 발생 시 슬레이브를 마스터로 자동 승격시키는 기능을 제공하는 도구로 MHA를 선택했습니다.
이 선택은 Orchestrator와의 비교를 통해 결정했습니다.
1. MHA (MySQL Master HA)
- 마스터 서버에 장애가 발생했을 때 자동으로 슬레이브 서버를 새로운 마스터로 승격시키고, 복제 체인을 재구성합니다.
설정의 단순성과 신속한 장애 대응 능력으로 인해 선택되었습니다.
2. Orchestrator
- 복제 구조의 시각적 표현, 자동 장애 감지 및 복구, 마스터 승격 등 고급 기능을 제공합니다.
그러나 Orchestrator의 고급 기능은 해축갤 서비스의 경우 필요 이상의 복잡성을 추가할 수 있으며,
MHA에 비해 설정과 관리가 더 복잡할 수 있습니다.
- 최근 Orchestrator 의 Maintainer 자리가 공석이라, 유지보수의 문제점이 있습니다. (관련 PR 링크)
결론
결국, master-slave 구성에 MHA를 도입하는 것은 해축갤 서비스의 높은 가용성,
신속한 데이터 복구 요구를 충족시키는 최적의 선택이라는 결정에 이르렀습니다.
정리
이번 글에서는 다음 3가지를 알아봤습니다.
1. 서비스 분석: 해축갤 서비스 특성에 따른 중요 데이터 식별 및 백업 필요성 평가.
2. 백업 전략 선택: 실시간 데이터 복제 방식, 특히 master-slave 구성 선정으로 결정.
3. 복구 전략 결정: MHA를 사용한 master-slave 구성으로 자동 승격 기능 구현 선택.
다음 글에서부터는 Master-Slave, MHA 의 동작 방식을 알아보고,
실제로 적용하는 글을 해보겠습니다!
참고
https://saramin.github.io/2021-09-28-mysql-group-replication/](https://saramin.github.io/2021-09-28-mysql-group-replication/
https://blog.seulgi.kim/2015/05/how-mysql-replication.html
https://www.slideshare.net/NHNFORWARD/mysql-nhn-forward-2018
https://1-7171771.tistory.com/151
'Project 해축갤 > 데이터베이스' 카테고리의 다른 글
| 손흥민 결승골 후 데이터 폭증: 해축갤에서의 3가지 인덱스 전략 (5) | 2024.03.26 |
|---|---|
| MySQL 인덱스 크기와 디스크 I/O 최적화: 데이터베이스 성능 향상 가이드 (4) | 2024.03.25 |
| MySQL 데이터베이스 복구 실패: 실험에서 배운 교훈과 데이터베이스 관리 전략 (5) | 2024.01.23 |