2025. 2. 16. 18:42ㆍSpring
들어가며: 호텔 표준 데이터 최신화의 시작
"36GB의 호텔 데이터 마이그레이션 해주세요."
호텔 표준 데이터 최신화 프로젝트에서 마주한 첫 번째 과제였습니다.
호텔 데이터는 단순한 flat한 구조가 아닌, 6개의 테이블로 분산되어 저장되어야 했습니다:

제가 생각한 이 마이그레이션의 핵심 요구사항은 "데이터 정합성"이었습니다.
하나의 호텔 데이터가 이 6개 테이블에 모두 성공적으로 저장되거나,
아니면 전혀 저장되지 않아야 했습니다("All or Nothing").
또한 기존 데이터가 있을 수 있어 INSERT가 아닌 UPSERT를 사용해야 했죠.
메모리 한계를 고려해 batch size를 100으로 설정했습니다.
36GB 전체를 한 번에 처리하는 것은 현실적으로 불가능했고, 실패 시 복구도 용이해야 했기 때문입니다.
첫 번째 문제: LockTimeoutException
단순하게 생각했던 배치 프로세스에서 예상치 못한 에러를 만났습니다:
while (true) {
int BATCH_SIZE = 100;
List<RawHotel> rawEanHotels = batchEanEnHotelsMapper.getRawEnHotels(BATCH_SIZE);
// ... 데이터 처리 ...
}
36GB의 데이터를 메모리 부하 없이 처리하기 위해 100건씩 끊어서 처리하는 단순한 while문 이었습니다.
하지만 개발 환경에서 첫 테스트를 실행했을 때, 예상치 못한 에러가 발생했습니다:
Error updating database. Cause: com.mysql.cj.jdbc.exceptions.MySQLTransactionRollbackException:
Lock wait timeout exceeded; try restarting transaction

보시다시피, 트랜잭션이 시작되고 첫 번째 호텔 데이터에 대한 UPSERT 요청부터 Lock이 걸리기 시작합니다.
그리고 2~100번째 호텔 데이터를 처리하면서 Lock이 계속 쌓여가죠.
결국 MySQL의 기본 Lock timeout인 50초를 초과하면서 트랜잭션이 롤백되는 상황이 발생했습니다.
실제 프로세스의 흐름을 더 자세히 들여다보면:

위 다이어그램처럼 하나의 트랜잭션 안에서 호텔 테이블 3개, 공급사 테이블 3개,
총 6개의 테이블에 대한 UPSERT 작업이 순차적으로 일어납니다.
문제는 단순히 6개 테이블에 대한 UPSERT가 아니라, 이걸 100건에 대해 반복한다는 점이었죠.
"100건의 데이터 처리에 50초가 넘게 걸린다고?" 뭔가 잘못됐다는 생각이 들었습니다.
트랜잭션 범위부터 의심해봐야겠다고 판단했죠.

첫 번째 최적화 시도: 트랜잭션 범위 최소화
코드를 살펴보니, 불필요한 작업이 트랜잭션 내에 포함되어 있었습니다:
위 다이어그램에서 볼 수 있듯이, 트랜잭션 범위에 불필요한 작업들이 포함되어 있었습니다.
try {
transactionTemplate.executeWithoutResult(status -> {
updateHotels(eanHotelEnDtos);
updateVendorHotels(eanHotelEnDtos);
});
} catch (Exception e) {
success = false;
}
먼저 트랜잭션을 열고
private void updateHotels(List<EanHotelEnDto> eanHotelEnDtos) {
upsertHotelMasterEn(eanHotelEnDtos);
upsertHotelDetailInfoEn(eanHotelEnDtos);
upsertHotelPhotoEn(eanHotelEnDtos);
}
private void upsertHotelDetailInfoEn(List<EanHotelEnDto> eanHotelEnDtos) {
// 1. Raw Data -> DTO 변환 : 트랜잭
List<UpsertHotelDetailInfoEn> upsertHotelDetailInfoEns = eanHotelEnDtos
.stream()
.map(eanHotelEnDto -> new UpsertHotelDetailInfoEn(
hotelCodeMap.get(eanHotelEnDto.getVendorHotelCode()),
eanHotelEnDto
))
.collect(Collectors.toList());
// 2. DB 에 upsert
batchEanEnHotelsMapper.batchUpsertHotelDetailInfoEn(upsertHotelDetailInfoEns);
}
private void upsertHotelMasterEn(List<EanHotelEnDto> eanHotelEnDtos) {
// 1. Raw Data -> DTO 변환
...
// 2. DB 에 upsert
...
}
private void upsertHotelPhotoEn(List<EanHotelEnDto> eanHotelEnDtos) {
// 1. Raw Data -> DTO 변환
...
// 2. DB 에 upsert
...
}각각의 DTO 변환, upsert 작업을 실행하게 됩니다.
이때 원본 데이터(JSON)를 DTO로 변환하는 작업이 트랜잭션 내에서 이루어지고 있었죠:
이 변환 작업은 순수하게 메모리 상에서 이루어지는 작업으로, DB 트랜잭션이 필요 없었습니다.
그래서 이를 트랜잭션 밖으로 분리하고 프로세스는 다음과 같이 변했습니다.
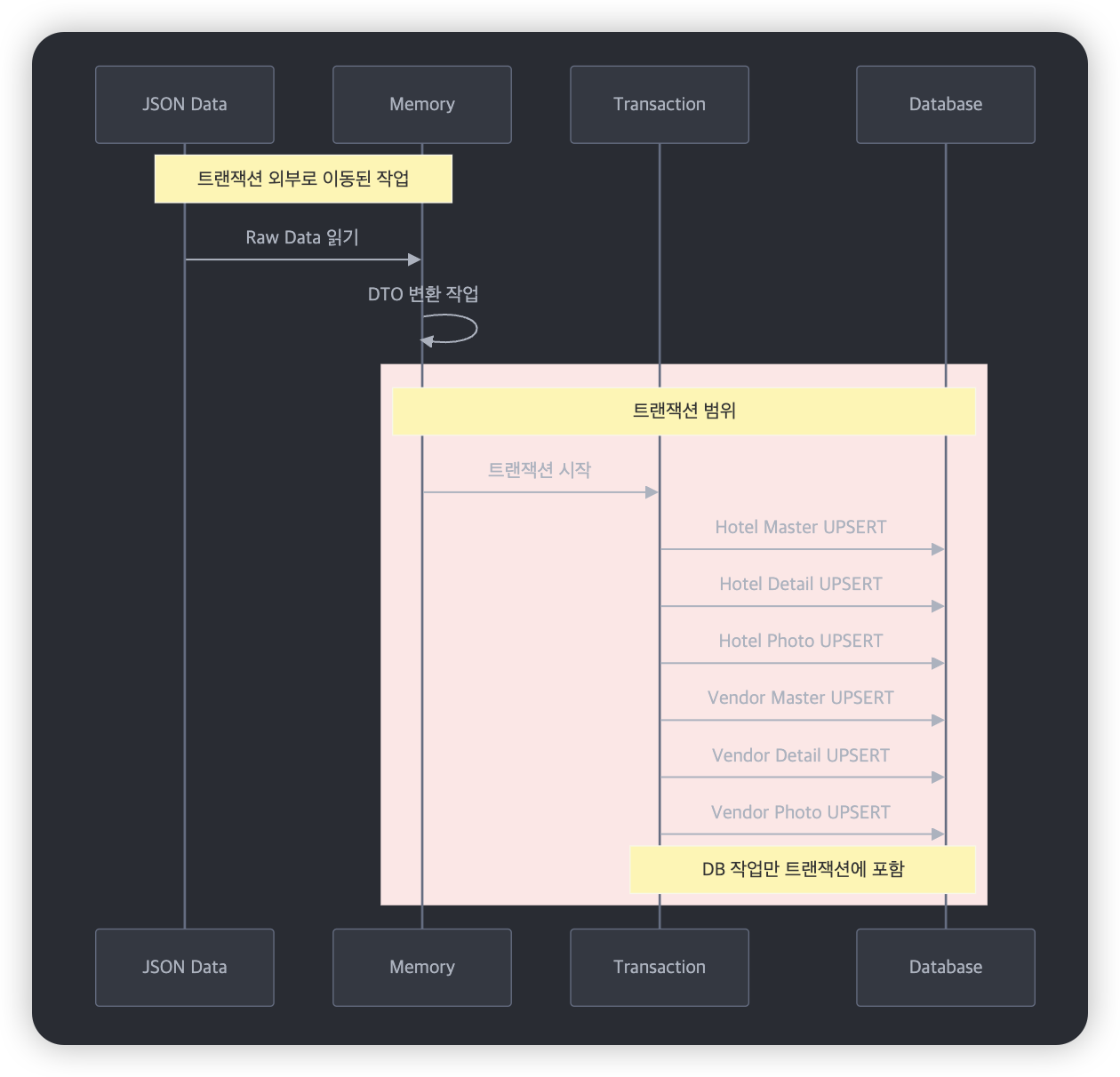
하지만 여전히 LockTimeoutException은 발생했습니다.
진짜 범인 발견: 인덱스의 영향
아무래도 DTO 변환은 Spring 의 메모리상에서 일어나는 작업이기 때문에
그렇게 오래 걸리는 작업은 아니입니다.
물론 트랜잭션에서 불필요한 작업이기 때문에 분리는 맞지만,
그렇다고 지금의 LockTimeoutException 이 일어날 만큼의 시간이 소요가 될거라는 생각이 안 났습니다.
정확한 근거를 위해, 성능 측정을 시작했습니다:

위 결과를 보고 다음과 같은 의문이 들었습니다.
“뭔 100건 upsert 하는 데, 17초나 걸리지…?”
내가 쿼리를 거지같이 짰나…? 싶은 자기 의심(?) 도 했습니다.
하지만 쿼리는 upsert 시에, 기존 데이터가 있는 지 확인하기 위해서 PK 를 활용하도록 했습니다.
그래서 속도가 느릴 이유도 없다고 생각했고요.
곰곰이 고민을 하던 찰나, 문득 인덱스? 라는 생각이 들어
각 테이블의 인덱스를 확인해보니 심각한 사실을 발견했습니다:
SHOW INDEX FROM HO_HOTEL_MASTER;
/*
- PRIMARY KEY (hotel_code)
- hotel_name_idx (hotel_name)
- location_idx (latitude, longitude)
- vendor_code_idx (vendor_code)
- status_idx (status)
*/
6개 테이블 모두 비슷한 수준의 인덱스를 가지고 있었고,
이는 UPSERT 작업을 매우 느리게 만들고 있었습니다.
원인 분석: B+Tree 인덱스와 UPSERT의 비밀
MySQL InnoDB의 기본 인덱스 자료구조인 B+Tree의 동작 방식을 자세히 살펴볼 필요가 있었습니다.
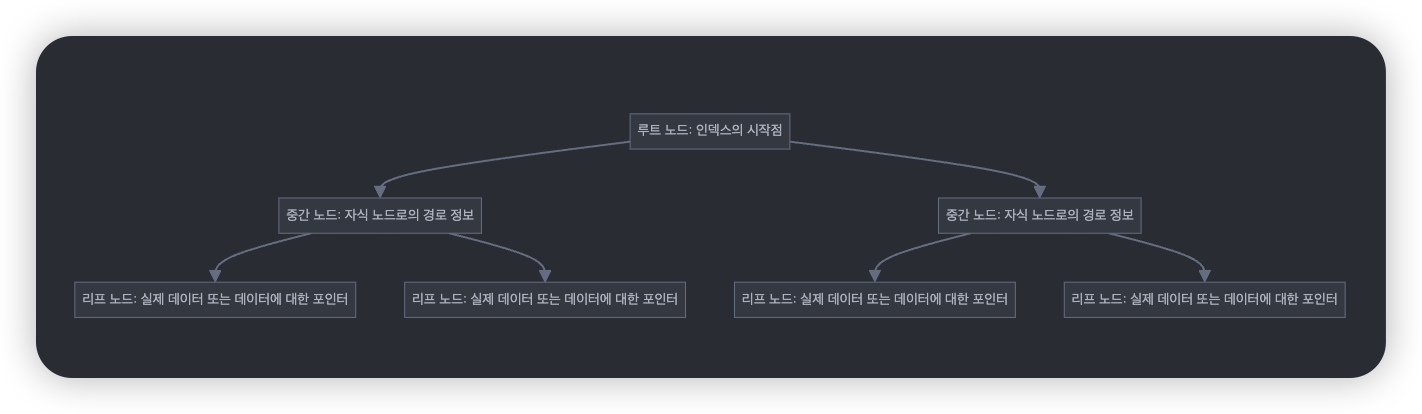
SELECT 쿼리와 UPSERT 작업의 차이를 비교해보면:
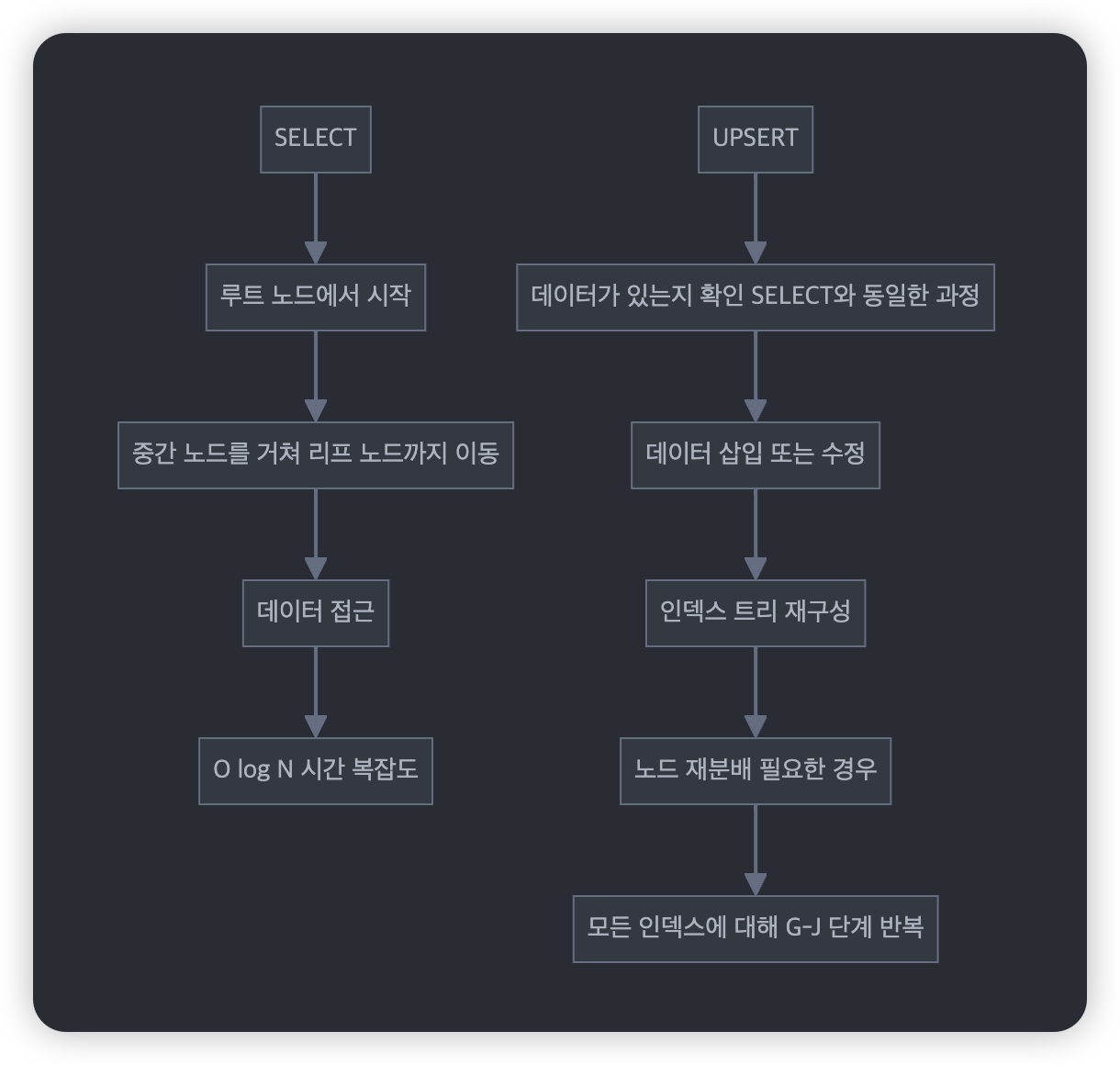
[SELECT]
1. 루트 노드에서 시작
2. 중간 노드를 거쳐 리프 노드까지 이동
3. 데이터 접근
4. O(log N) 시간 복잡도
[UPSERT]
1. 데이터가 있는지 확인 (SELECT와 동일한 과정)
2. 데이터 삽입 또는 수정
3. 인덱스 트리 재구성
4. 노드 재분배 (필요한 경우)
5. 모든 인덱스에 대해 2-4 반복
우리의 경우를 계산해보면:
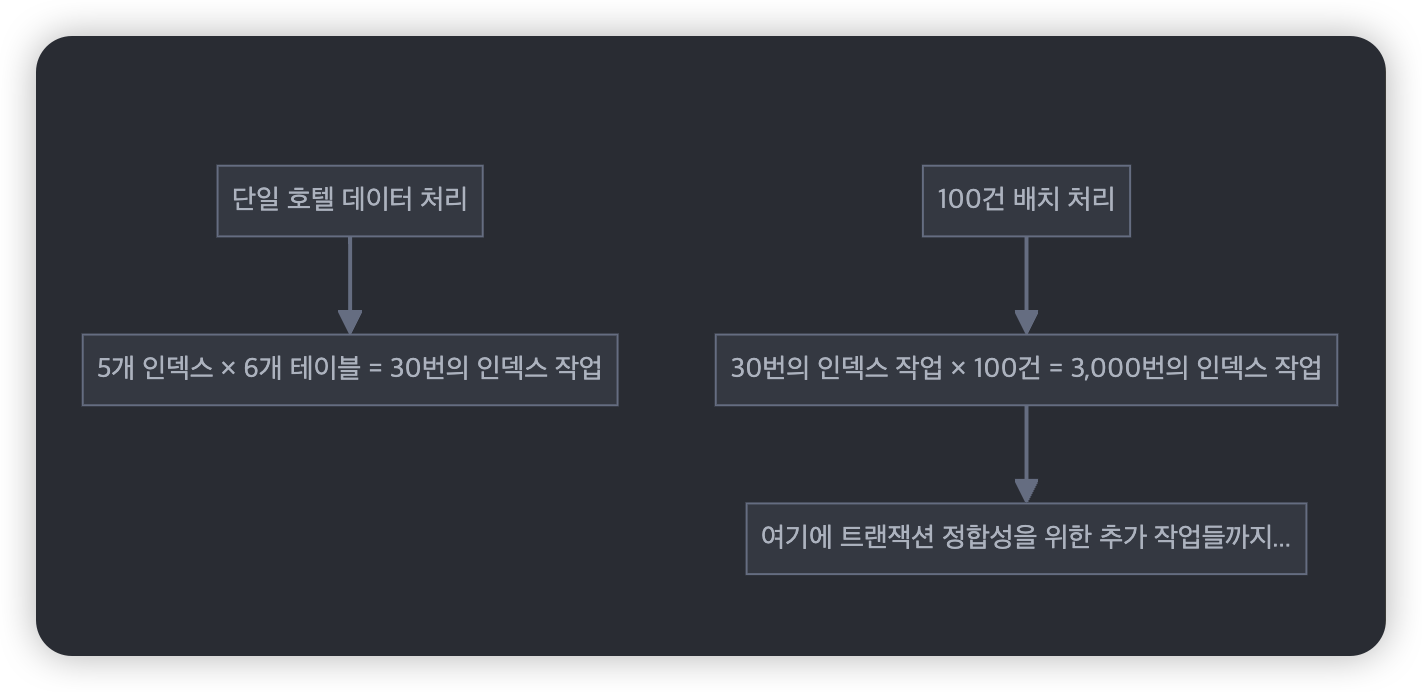
코드에서도 이런 복잡성이 드러났습니다:
private void updateHotels(List<EanHotelEnDto> eanHotelEnDtos) {
upsertHotelMasterEn(eanHotelEnDtos);// 5개 인덱스
upsertHotelDetailInfoEn(eanHotelEnDtos);// 5개 인덱스
upsertHotelPhotoEn(eanHotelEnDtos);// 5개 인덱스
}
private void updateVendorHotels(List<EanHotelEnDto> eanHotelEnDtos) {
upsertVendorHotelMasterEn(eanHotelEnDtos);// 5개 인덱스
upsertVendorHotelInfoEn(eanHotelEnDtos);// 5개 인덱스
upsertVendorHotelPhotoEn(eanHotelEnDtos);// 5개 인덱스
}
이것이 Lock Timeout의 원인이었습니다.
하나의 UPSERT가 완료되기도 전에 다음 UPSERT가 대기하면서 Lock이 쌓여갔고,
결국 Timeout이 발생한 것이죠.
해결 방안: 인덱스 전략 재수립
마이그레이션을 위한 새로운 전략을 수립했습니다:
-- 1. 마이그레이션 전: 불필요한 인덱스 제거
ALTER TABLE HO_HOTEL_MASTER DROP INDEX hotel_name_idx;
ALTER TABLE HO_HOTEL_MASTER DROP INDEX location_idx;
-- PRIMARY KEY와 필수 인덱스만 유지
-- 2. 데이터 마이그레이션 -- 기존 코드 그대로 활용
-- 3. 마이그레이션 후: 인덱스 재생성
ALTER TABLE HO_HOTEL_MASTER ADD INDEX hotel_name_idx (hotel_name);
ALTER TABLE HO_HOTEL_MASTER ADD INDEX location_idx (latitude, longitude);
코드도 일부 수정했습니다:
public void updateHotelEn() {
// 트랜잭션 밖에서 데이터 준비
List<EanHotelEnDto> eanHotelEnDtos = rawEanHotels.stream()
.map(rawEanHotel -> new EanHotelEnDto(rawEanHotel.getJsonHotel()))
.collect(Collectors.toList());
// 최소한의 트랜잭션 범위
transactionTemplate.executeWithoutResult(status -> {
updateHotels(eanHotelEnDtos);
updateVendorHotels(eanHotelEnDtos);
});
}
개선 효과와 새로운 인사이트
성능이 꽤나 개선되었습니다:
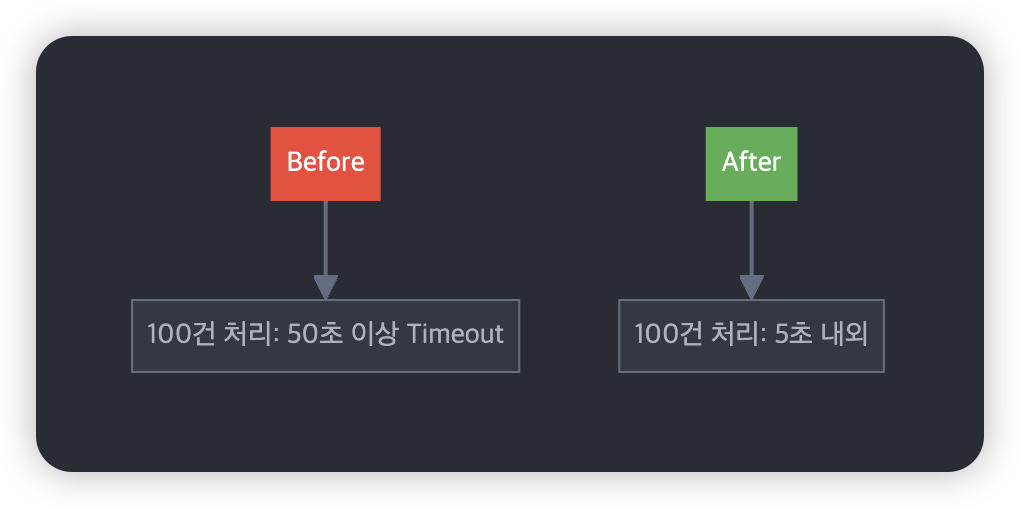
이 경험을 통해 몇 가지 중요한 인사이트를 얻었습니다:
- 인덱스의 양면성: SELECT 성능을 위해 무심코 추가한 인덱스가 데이터 변경 작업에서는 독이 될 수 있습니다.
- 대용량 데이터 처리 전략:
- 배치 사이즈 최적화
- 불필요한 인덱스 제거
- 트랜잭션 범위 최소화
- 성능 측정의 중요성: 문제의 원인을 찾기 위해서는 각 단계별 정확한 측정이 필요합니다.
남은 과제와 고민들
현재 코드에는 여전히 개선의 여지가 있습니다:
while (true) {
// 1. Multi-Threading 적용 가능성
// 2. 배치 사이즈 동적 조정
// 3. 실패 복구 전략 고도화
}
특히 Multi-Threading 적용은 신중한 검토가 필요합니다. Connection Pool 관리와 Lock 경합 문제를 고려해야 하기 때문입니다.
- Lock 경합의 경우, 하나의 36GB 파일 안에 동일 호텔에 대한 정보가 들어오는 경우 x
- Multi-Threading 의 경우, 유저가 없는 새벽 Batch 에 하도록 해 Connection Pool 점유
이렇게 고민을 하는 중입니다.
'Spring' 카테고리의 다른 글
| 알림톡과 예약 시스템의 트랜잭션 분리 - 아웃박스 패턴 도입기 (2) | 2025.01.29 |
|---|---|
| 비즈니스 확장성을 고려한 알림톡 발송 시스템 개선기: 전략 패턴의 실전 적용 (2) | 2025.01.26 |
| 회사의 기존 인증/인가 시스템 유지보수 및 새로운 방안 도입 (1) | 2024.10.13 |
| HttpMediaTypeNotAcceptableException: Could not find acceptable representation (0) | 2023.10.30 |
| 비밀번호의 암호화 위치, 엔티티 내부 vs 서비스 계층? (2) | 2023.10.17 |