2023. 8. 3. 10:28ㆍ광고차단 머신러닝
2023.08.03 - [산학협력프로젝트] - BERT 로는 노오력이 부족하다, RoBERTa 로 성능 개선
BERT 로는 노오력이 부족하다, RoBERTa 로 성능 개선
2023.08.01 - [산학협력프로젝트] - "너가 만든 거 유효하긴 해?", BERT, Random Forest 성능테스트 하기 "너가 만든 거 유효하긴 해?", BERT, Random Forest 성능테스트 하기 동전에 이어 이번에는 나무...? Random Fo
xpmxf4.tistory.com
저번 포스팅을 보시고 오는 것을 추천드립니다!!
저번 글에서 충격적인 것을 발견했었는 데, 바로

오차율이 소수점 맨 아래까지 똑같다는 것입니다...
아무리 제가 머신 러닝 쪽을 처음 해본다고는 하지만,
어쨌든 통계라는 것을 이용해 예측을 하는 데
저렇게까지 확률이 같다는 것은 틀리다는 것은 알 수 있습니다.
그리고 BERT 보다 개량된 모델인 RoBERTa 는
조금이라도 성능이 나올 것이라고 예측했는 데
아얘 똑같은 것도 이상했습니다.
그렇다면 대체 어디서 잘못됐을까?

소수점까지 완벽히 같은 오차율을 보고 한동안 멘붕이 오다
이성을 차리고 어떻게든 나의 프로젝트를 억까(?)를 해보니
생각해 본 2, 3 가지였다.
- Fine Tuning을 위한 데이터셋의 양이 부족하다.
- 모델의 Fine Tuning 하는 코드가 잘못됐다.
- Epoch 가 적었다.
- 테스트 목적의 데이터셋 양이 부족하다.
이 중 일단 2번, Fine Tuning 방법은 가능 가능성이 낮다고 생각했다.
머신러닝을 처음 해보는 거라서, 학습할 때는 힘들었지만
사실 굉장히 초보적인 수준으로 학습을 진행한 방법이다.
그렇기 때문에 애초에 학습을 하는 코드는
개선의 여지가 있다만 오류가 날 정도는 아니다
라는 생각이 들었습니다.
그렇다면 다음 3가지 원인으로 좁혀졌습니다.
- Fine Tuning 을 위한 데이터셋의 양/퀄리티 부족
- Epoch 가 적었다.
- 테스트 목적의 데이터셋 양/퀄리티 부족
Epoch 가 적었을까?
먼저 Epoch 에 대해 아래 영상의 12:00 분부터 설명을 보시면 좋겠습니다.
즉, 얼마나 전체 학습 데이터를 돌 거냐라는 횟수입니다.
제 RoBERTa는 처음에 학습을 5번만 돌렸습니다.
# 학습
model.train()
# for epoch in range(5): // 여기에서 5 번만 돌도록 설정했었고
for epoch in range(10): // 10으로 바꿨다!
for batch in dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
outputs = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f'Epoch {epoch + 1}, Loss {loss.item()}')그래서 이게 성능이 제대로 안 나오나 싶어서
epoch를 10으로 늘려서 학습을 진행한 뒤에,
다시 한번 성능을 테스트해 봤지만

신기하게도 오차율은 그대로 정확히 그대로였습니다.
따라서 epoch의 문제는 아니라는 결론을 내렸습니다.
그렇다면 데이터셋의 양 or 퀄리티, 뭐가 문제일까?
즉, Fine Tuning 시의 데이터셋들과
모델 예측 시에 사용한 데이터셋들의 양/퀄리티에 문제가 있다는 결론이 나왔습니다.
먼저 퀄리티를 생각했었는 데
프로젝트 시작 시에 학습, 예측 데이터셋들에 대한
사전 라벨링을 어떻게 해야 할 지에 대해 생각했었는 데
산학협력 프로젝트, 광고 차단 오토로 돌리기 (졸업 하고 싶어요ㅠ)
1. 오늘의 주제 이번에 진행한 프로젝트는 산학협력 프로젝트입니다! 주제는 '기계 학습을 통한 광고 사이트 자동 차단 프로그램' 입니다. 이미 광고 사이트 차단해주는 프로그램 있지 않아요? Ad
xpmxf4.tistory.com
위 글에서 얘기했던 것처럼, 애초에 모델이 없는 데
광고 사이트인지 자동으로 라벨링을 할 수가 없다는 결론에
수동으로 라벨링을 진행했습니다.
수작업으로 진행했기에 데이터셋들에 대한 퀄리티가
100%는 아니더라도, 괜찮지 않을까 라는 생각을 했습니다.
광고/비광고 사이트가 생긴 거로 구분하기가 명확했거든요.
따라서 양의 문제일 거라고 생각했습니다.
생각해 보니 Fine Tuning 시에는 1,000 개의 데이터를 사용했지만
모델의 예측 테스트할 때는 고작 200개 밖에 진행하지 않았습니다.
그래서 학습 시에 사용했던 학습 데이터 1,000 개로
모델 예측을 해보자는 결론이 들었습니다.
바로 테스트해 보자~
Fine Tuning, 예측용 데이터들은 별도의 파일들로 존재합니다.
고로 경로만 수정해서 바로 테스트를 해봤습니다.
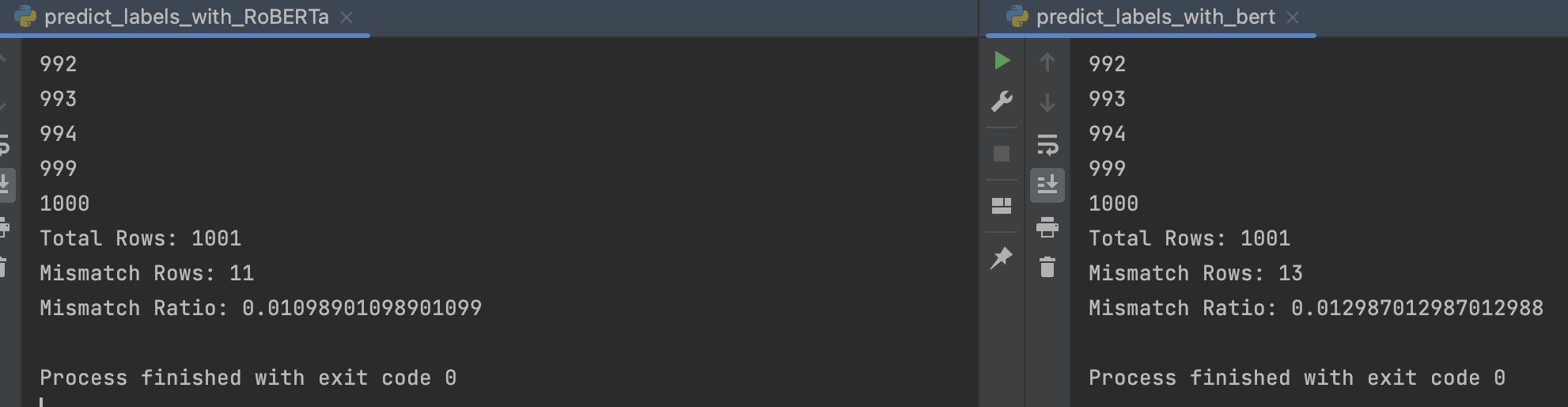
드디어 제대로,,, 나옵니다,,,
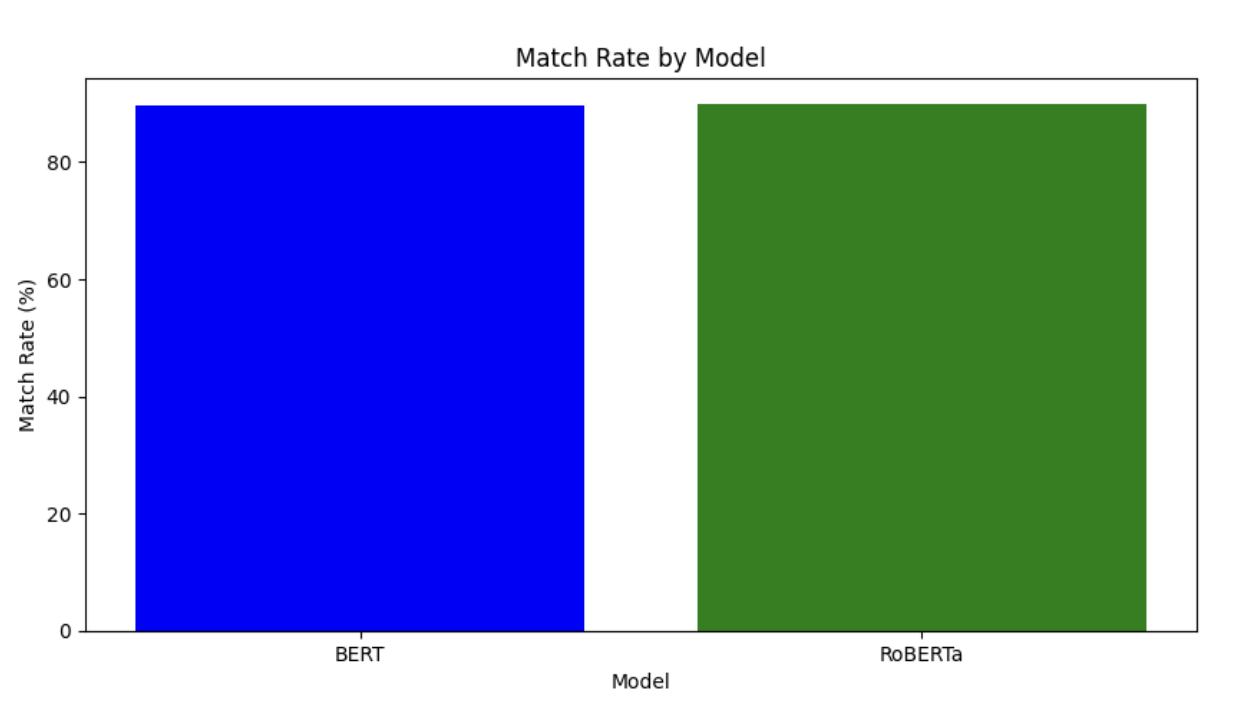
성능은 BERT 89.610%, RoBERTa 89.910% 로 나옵니다.
어째 제대로 테스트해보니 성능은 내려갔다만
그래도 제대로 된 결과물이 나왔습니다.
이왕 하는 거 다른 모델들도 다 테스트해보자!
이렇게 된다면 기존의 RF 모델과 가중평균 모델 1(BERT+RF)도
200개의 데이터로 예측을 했기 때문에 다시 테스트해야 합니다.
그리고 새로운 가중평균 모델 2(BERT+RF+RoBERTa) 도 만들어보고
성능을 체크해 보기로 했습니다!
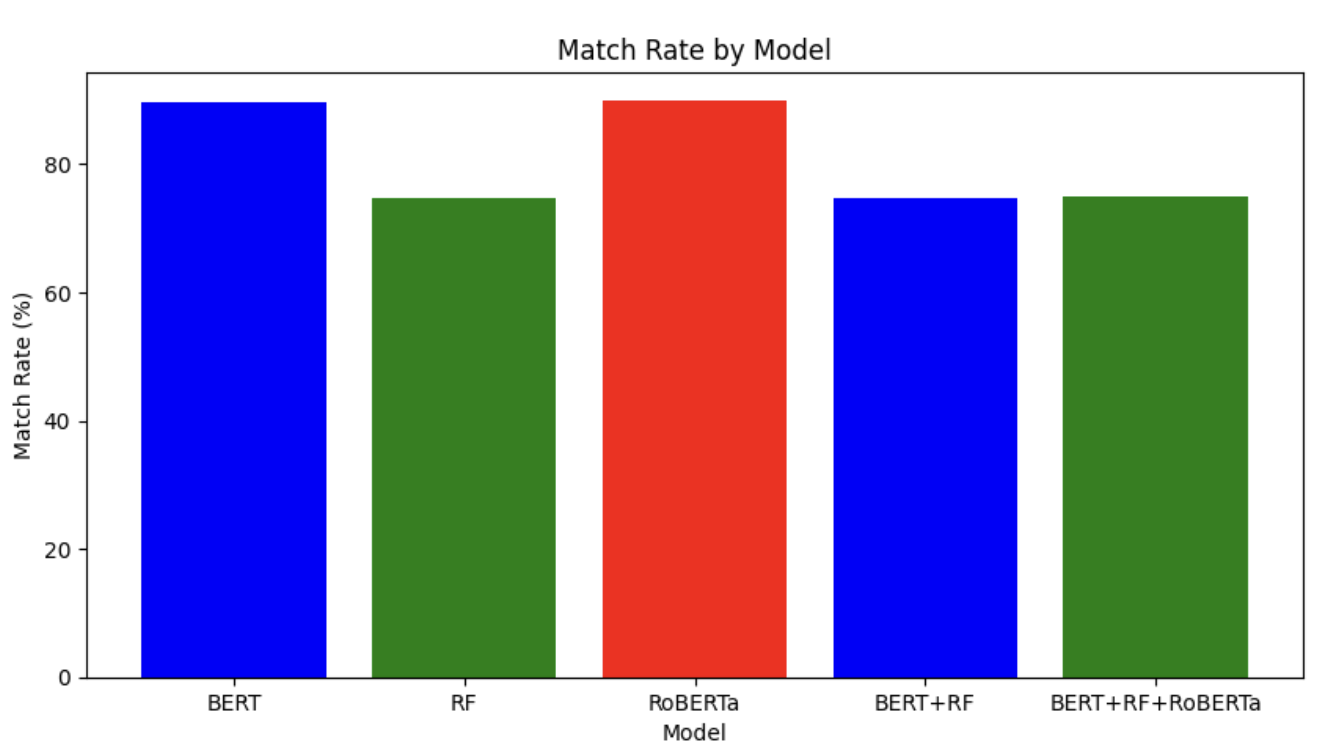
'BERT': 89.610, # BERT 모델의 일치율
'RF': 74.725, # RF 모델의 일치율
'RoBERTa': 89.810, # RoBERTa 모델의 일치율
'BERT+RF': 74.825, # BERT+RF 가중평균 모델1
'BERT+RF+RoBERTa': 74.925, #BERT+RF+RoBERTa 가중평균 모델2그전에는 RF의 성능이 제일 높게 나왔었는 데
다른 데이터셋으로 테스트하니 RoBERTa 하나만 사용한 게
성능이 89.810% 로 제일 좋다고 나옵니다!
결론
생각지도 못한 데서 이상한(?) 결과가 나와서 정말 당황했지만,
하나하나 오류 예측을 하다 보니 데이터셋의 양이 부족해서 생긴 일이라는 것을 알고
데이터셋의 중요성을 알게 되었습니다!
'광고차단 머신러닝' 카테고리의 다른 글
| 어째서 광고 차단 프로그램의 규칙은 공개되어 있을까? (11) | 2023.08.09 |
|---|---|
| ???:"휴먼, 당신의 말은 이해할 수 없습니다.(진짜모름)", 자연어처리를 위한 BERT 선택의 이유와 근거 (11) | 2023.08.07 |
| BERT 로는 노오력이 부족하다, RoBERTa 로 성능 개선 시도했는 데 결과물이...? (0) | 2023.08.03 |
| "너가 만든 거 유효하긴 해?", BERT, Random Forest 성능테스트 하기 (0) | 2023.08.01 |
| 동전에 이어 이번에는 나무...? Random Forest Model 은 뭘까 (0) | 2023.07.31 |